后端开发常见层式结构
后端开发常见层式结构
#TODO 论文复现
系统设计案例system-design-primer· GitHub
后端开发常见层式结构:时间轮(TimingWheel)、跳表、LSM-Tree
- 海量并发的定时任务组织:时间轮[linux内核,skynet,kafka,netty]
- 高并发读写的有序结构组织:跳表[redis,lucene,rocksdb]
- 空间利用率以及写性能高的磁盘数据组织:LSM-Tree[leveldb(google的k-v) rocksdb(布式关系型数据库) tidb(mysql) cockroachdb(pg)]
都是按照层来组织数据的
时间轮TimingWheel
数据组织
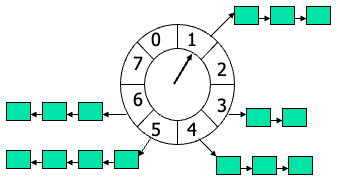
普通时间轮,每个链表存储的是此时刻的任务,在ptr指向此时刻的时候执行此时刻的任务
层级时间轮,按照任务的优先级进行任务划分,在分针运行到下一个时间块的时候,秒针任务空间会被重置为第二个分钟块的任务,时针以此类推
kafka中用的也是三级时间轮1ms✖️20ms✖️400ms
在自己设计时间轮的时候,需要从三方面考虑,可以设置为参数方便调整:
- 设计最小时间精度 支持最小的时间块
- 设计最大时间范围 超过时间范围会出现错误
- 设计层级个数 决定了映射的频繁程度
应用场景
时间轮在海量多线程并发的情景下,需要考虑锁的问题
锁本质上是希望同一时刻只有一个线程去操作DS,提升性能两条路子:
- 减少时间复杂度(降低此DS占用线程 cpu的时间)时间轮
- 在更细粒度上加锁(让多个线程同时操作本DS的细粒度DS,不会浪费每个线程的cpu时间)任务队列APscheduler+redis,跳表也是
论文和实现
论文指路 没有中文版,时间轮被提出的论文,还有一个PPT,文章可能以后有用 有时间可以读一读论文,甚至可以翻译一下,照着其他博客实现几个小的demo,视频上的东西先做初步了解
跳表Skip List
多层级的有序链表
跳跃表 — Redis 设计与实现
数据组织
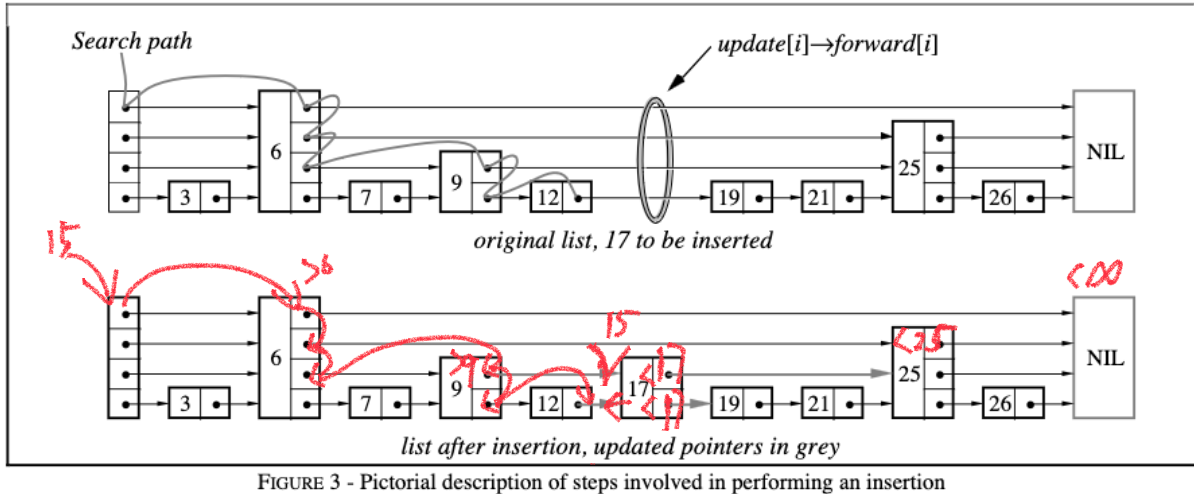 单层级链表时间复杂度为O(n),跳表将其降低为O(log2n)和二分一样,每次查找能够排除一半的节点
单层级链表时间复杂度为O(n),跳表将其降低为O(log2n)和二分一样,每次查找能够排除一半的节点
增加节点的时候会赋予新元素随机层数,其实不影响
跳表的增删改查都需要先查,核心就是不断比较层数之间,如果被夹住中间没有节点了,那就是应该插入的位置
跳表的作者本来想得是每隔一个节点设置一个相同的层级,每次查询恰好排除一半,是这样
3-------3
2---2---2---2
1-1-1-1-1-1-1-1
但是发现每次增删的时候会破坏所有的层级结构,需要重新构建
插入节点的时候,层数往上以每层1/2概率决定是否累加,下一层,这样当数据足够大的时候(在redis中为256个节点的时候稳定)时间复杂度为
应用场景
跳表适应多线程写的,因为在更细粒度上加锁,只需要锁住最高高度以及自己身边的两个节点即可。
- redis的Zset是用跳表实现的有序集合为什么是用跳表而不是红黑树?
- 红黑树不会浪费层数但是也是log2n,而且空间没浪费时间复杂度稳定
- redis是数据库,需要做范围查找,红黑树不是很合适会有很多的回溯和比较
- 为什么不用B+ 因为B+的搜索为h * log2n 查找的时候会包很多比较每次比较一层都是 log2n
📝Note
跳表适合组织内存数据,而B+树适合组织磁盘数据。
我们把每一个索引的大小设置为磁盘的页大小证书倍,每次在B+树里行进一个高度,都要进行一次磁盘的IO,h决定了磁盘的IO数量
红黑和跳表高度太高了,B+更扁平
pg索引用的是B树,mysql是B+
论文和实现
LSM-Tree
日志结构合并树,不是单纯的数据结构,而是磁盘文件组织方式 一种非常复杂的复合数据结构,它包含了 WAL(Write Ahead Log)、跳表(SkipList)和一个分层的有序表(SSTable,Sorted String Table)。
数据组织
| 比较 | B+ | LSM-tree |
|---|---|---|
| 解决的问题 | 读多写少 | 写多读少 |
| 空间利用率 | 分裂时候利用率<50% innodb157G | 空间利用率好 myrocks40-50G |
| 时间复杂度 | 稳定O(logn) | O(n)-O(1) |
📌Tip
不同的存储设备延迟对比
磁盘随机io 寻道(8-12)+旋转(7200r/4ms)+传输(50M/s 0.3)=10ms左右
内存顺序io 10ns左右,100w倍的差距
磁盘随机<<磁盘顺序≈内存随机<<内存顺序
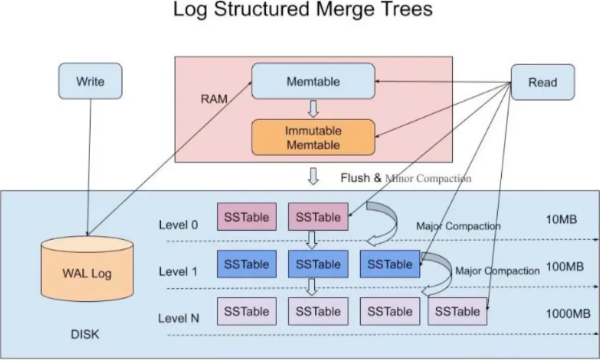
使用跳表保证内存中有序,然后写到磁盘里,RAM中有只读的内存和可写的内存。当写入内存达到阈值会变为不可写的内存块并写入level0,在此level可能会出现两个跳表相同的key
根据数据操作的热度进行分层,level往下逐渐归并排序并合并文件,到最后一个level基本都是冷数据,占据文件的90%,其他的热数据占据10%
因为在不断的合并所以占用空间少,以附加日志的方式写入,总是在文件末尾不断顺序IO。
在level0和层与层之间可能出现相同的数据,在每一个文件中加入布隆过滤器,先概率判断再去搜索。
应用场景
- myrocks,不仅使用LSM-Tree而且还实现了事务
- 日志结构的存储引擎
- 高性能,适合频繁写入的场景
- 内部维护 kv 对(适合应用于 kv 存储)
- 内部维护了多种不同的数据结构,每种结构都进行了针对性优化,数据在不同结构之间同步
论文和实现
Last Edit: 2025-04-13 22:01:52