part2-pandas
part2-pandas
使用pandas发现周期行为
需求
现有一堆发包记录,从其中发现周期发包的行为
需求是很主流的需求,ssh经常是每隔30秒15秒周期发包的
日志格式也很规律
| time | src_aaddr | dest | other |
|---|---|---|---|
| 2022-01-22 20:51:05 | 192.168.0.5 | 172.16.0.1 | ... |
| 2022-01-26 20:51:10 | 192.168.0.5 | 172.16.0.1 | ... |
| 2022-01-26 20:51:15 | 192.168.0.5 | 172.16.0.1 | ... |
像这样同源的每次都是隔五秒的就是可能存在的周期发包行为
日志量可大可小
解决过程
先观察数据特征,要求发现周期行为首先确定,发送主体是由 source: 源ip+目的ip+目的端口 唯一确定的,再就是时间,这四个列比较重要
对数据进行预处理,使用pd读取csv,如果文件很大就按字节读取,慢慢分割,攒够多少行了进行处理,把行中不规律的数据补齐,取个样打印一些看看有没有异常值,dtype转换比如时间数字等,会提高读取速度
进行分类,读取之后按照不同主体进行分类,分割出每个主体的df,此时我们拥有了每个source的发包记录,按照发包时间排列。
确定对哪个维度建模,一开始想的是,时间为横轴ip纵轴,这样就可以统计一串bit,利用这个建立坐标系,使用回文检测类似的发现其中的周期
后来发现时间不是一个好维度,随着时间增长,数据冗余会非常高,而且算法也很难找
后来看应该是维度找的不对,周期发包,那么肯定时间间隔就相同,时间间隔的计算就是使用shift diff,让本次发包的时间戳减去上一次,就得到了一个时间间隔
此时如果做坐标系,就是找出所有时间间隔相同,即线为直线的片段
但是此时继续把时间间隔相位想减,得到时间间隔的差,这时,只要这个差为0那么就说明有两个时间间隔相同,也就是有三个包发包间隔相同
此时得到的是为0的记录再往上两个记录都是属于间隔发包的,往上两位都置为0
可以利用上面的思路,先把这一列bool化,shift(-1),再和前一列做或操作,重复一次就实现效果了
写个小demo测试一下
from functools import reduce
import numpy as np
import pandas as pd
a = [1, 2, 3, 4, 4, 2, 1, 5, 5, 6, 7, 8, 0, 0, 0, 0, 0, 0, 7, 6, 5, 8, 2, 2, 2, 2, 1] # 假设这是时间间隔
b = []
for i in range(1, len(a)): # 生成测试发包序列
b.append(reduce(lambda x, y: x + y, a[:i]))
del a[-1]
print(a)
print(b)
s = {"date": b, "diff1": a}
df = pd.DataFrame(s)
df["diff1"]=df["diff1"].replace(0,np.nan)
df["diff2"]=df["diff1"].diff()
df["delta_mask"]= (df["diff2"] == 0)
df["delta_mask1"]=df["delta_mask"].shift(-1).fillna(False) | df["delta_mask"]
df["delta_mask2"]=df["delta_mask1"].shift(-1).fillna(False) | df["delta_mask1"] # 把为0的上三行都变为True
df1=df[df["delta_mask2"] == True]
# 在分界处分开
list_of_df = np.split(df1.copy(), np.flatnonzero(np.diff(df.index) != 1) + 1)
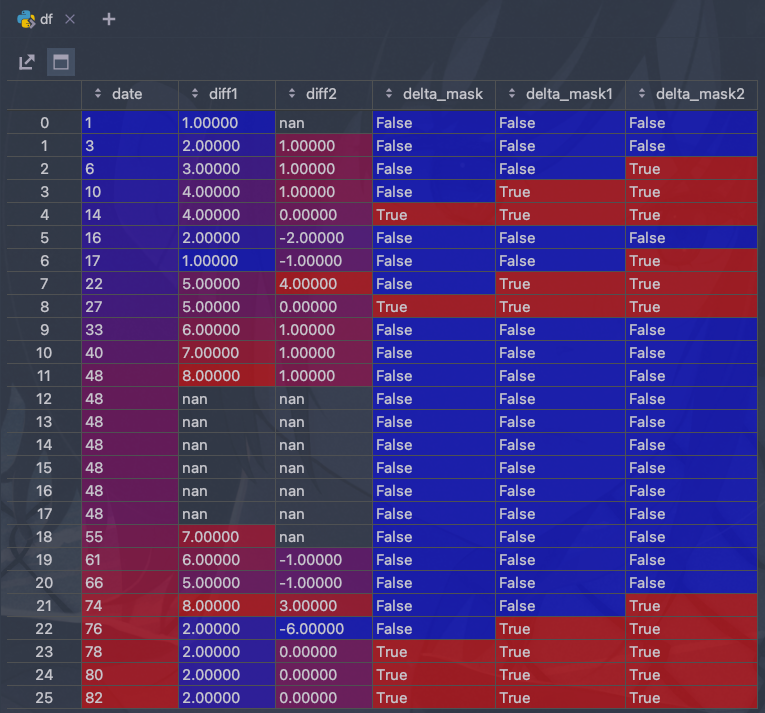
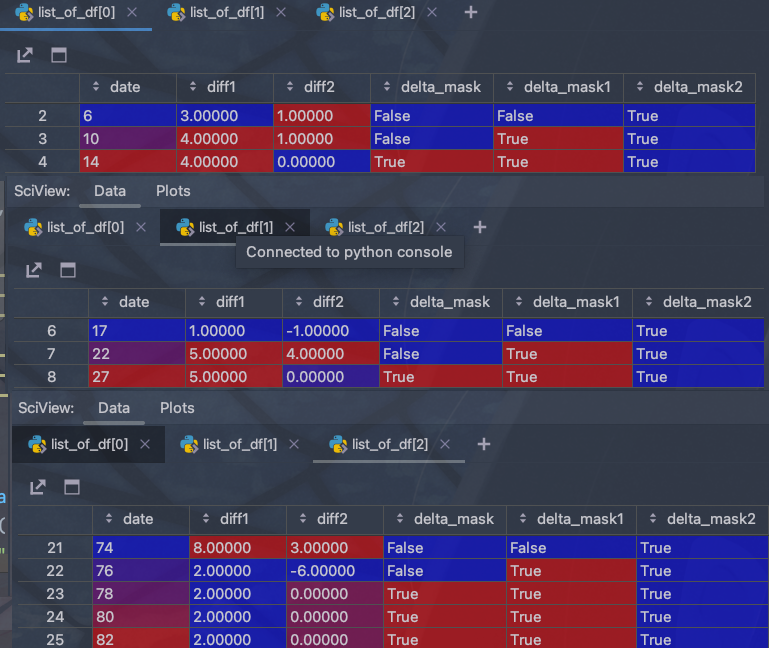
中间一些细致的需求,比如转nan处理边界啥的,一个地方一个样,就不写了帮不上啥,主要还是理解思路,操作照着handbook和文档都好说
导出json常用参数
path_or_buf: [string or file handle, optional]可以指定对象为文件路径或者为DataFrame,如果不指定,则返回结果为一个字符串。
orient: [string],指定为将要输出的JSON格式。其中我们输入的对象可能为Series或者为DataFrame:
Series: 默认索引为index,也就是行。允许的值输出形式有:{'split','records','index'}
DataFrame: 默认索引为columns,也就是列索引。允许的值输出形式有:{'split','records','index','columns','values'}
JSON字符形式的输出格式类型:
'split':将行索引index,列索引columns,值数据date分开来。dict like {'index' -> [index], 'columns' -> [columns], 'data' -> [values]}。
'records':将列表list格式,以[{列名->值},..]形式输出。list like [{column -> value}, … , {column -> value}] # 这个是常用的,每行一个元素
'index':将字典以{行索引:{列索引:值}}以这种形式输出dict like {index -> {column -> value}}。
'columns':将字典以{列索引:{行索引:值}}以这种形式输出 dict like {column -> {index -> value}}。
'values':就全部输出值就好了
'table': 这个输出有点复杂,具体描述该文件。dict like {'schema': {schema}, 'data': {data}} describing the data, and the data component is like `orient='records'`.。到时候实现一下即可了解
date_format: [None, 'epoch', 'iso'],日期转换类型。可将日期转为毫秒形式,iso格式为ISO8601时间格式。对于orient='table',默认值为“iso”。对于所有其他方向,默认值为“epoch”。
double_precision: [int, default 10],对浮点值进行编码时使用的小数位数。默认为10位。
force_unit: [boolean, default True],默认开启,编码位ASCII码。
date_unit: [string, default 'ms' (milliseconds)],编码到的时间单位,控制时间戳和ISO8601精度。“s”、“ms”、“us”、“ns”中的一个分别表示秒、毫秒、微秒和纳秒.默认为毫秒。
default_handler : [callable, default None],如果对象无法转换为适合JSON的格式,则调用处理程序。应接收单个参数,该参数是要转换并返回可序列化对象的对象。
lines: [boolean, default False],如果“orient”是“records”,则写出以行分隔的json格式。如果“orient”不正确,则会抛出ValueError,因为其他对象与列表不同。
compression: [None, 'gzip', 'bz2', 'zip', 'xz'],表示要在输出文件中使用的压缩的字符串,仅当第一个参数是文件名时使用。
index: [boolean, default True],是否在JSON字符串中包含索引值。仅当orient为“split”或“table”时,才支持不包含索引(index=False)。