twitter爬虫
twitter爬虫
推特反爬机制稍微严一些,但是也不是很难突破。 这次爬虫主要是练多进程的使用
分析请求
首先找请求,大小太离谱的都不要, 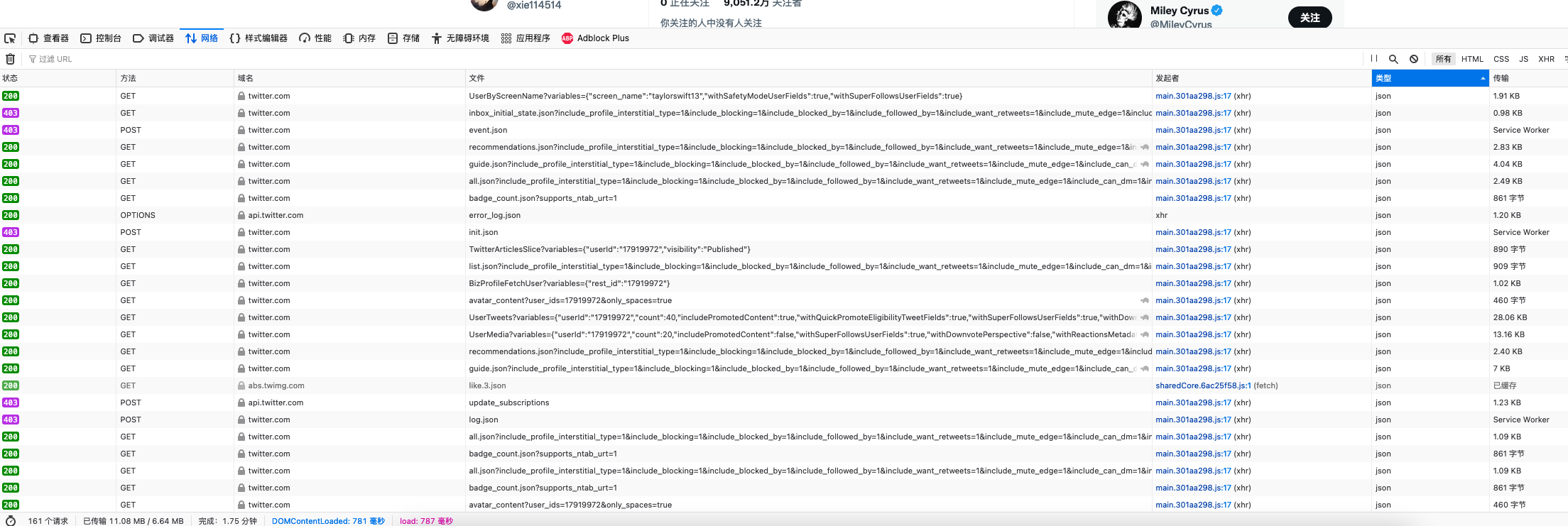
因为网页是滑动的,座椅每次下滑看看他加载哪些,找这些里面的数据。
一开始锁定的是all.json和guid.json后来发现guid.json返回的是边栏的推荐,all返回的是一些信息,这些信息也小小的误导了我
后来找到是这个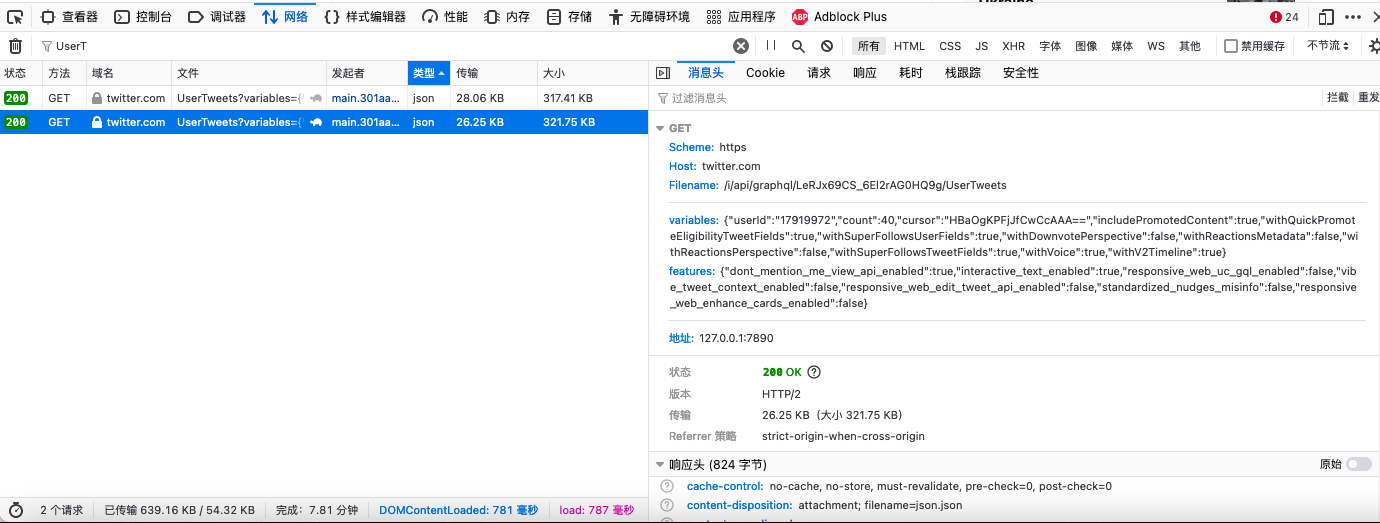
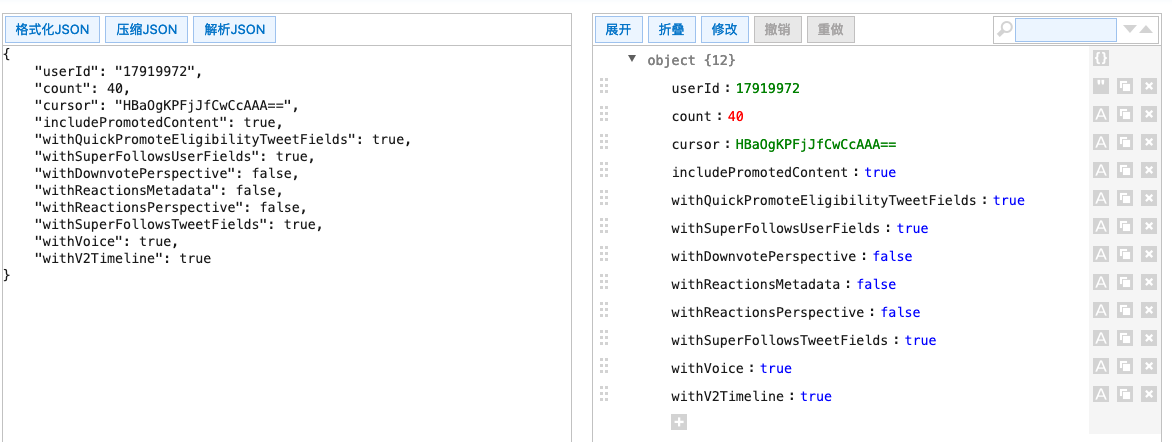
发现每次查询变化的都是这个cursor,因为之前all里面有很多信息,我以为这个cursro是计算出来的,所以就在js里面逆向找片段,非常难找,最后找到头发现,是这次的json里面带着下次的标
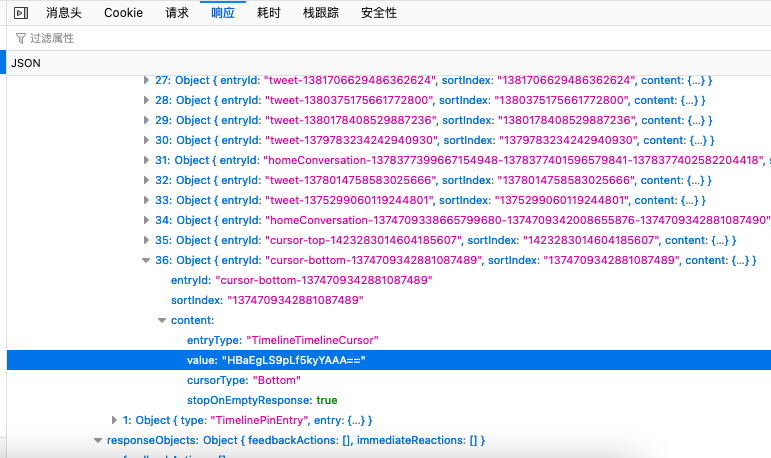
返回的json里面基本上包含了所有的内容。
重发请求
直接在浏览器里面重发返回403,以为是服务器有反爬,然后把这个请求复制curl放到postman里面去,重发得到了数据
猜测是有些请求头没带上,推特自己的请求头里面有好几个自定义的参数,估计是不带上就发不了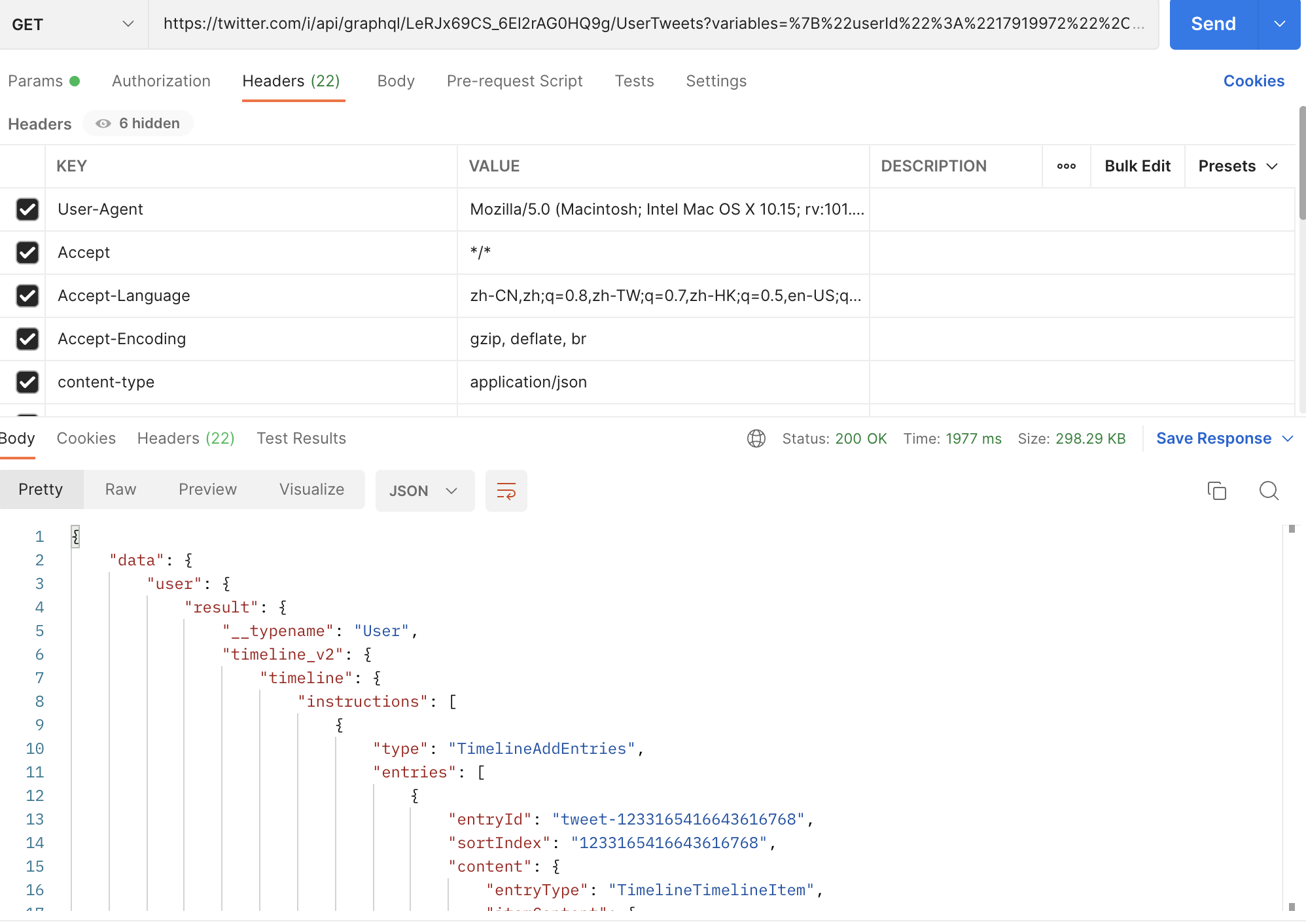
之后在python里请求就可以了,参数很多配起来麻烦
推文实际上在里面就有了,但是为了详细一点,顺手把评论第一页也爬一下
接口是TweetsDetail
Click to see more
import requests
cookies = {
...
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:101.0) Gecko/20100101 Firefox/101.0',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
# 'Accept-Encoding': 'gzip, deflate, br',
'content-type': 'application/json',
'x-twitter-auth-type': 'OAuth2Session',
'x-twitter-client-language': 'zh-cn',
'x-twitter-active-user': 'yes',
'x-csrf-token': '1b73c3ff3f8905027c09c8....1c1c3d6a65c07e4b67f2f67c715a0728ccd2bb445956c',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'authorization': 'Bearer AAAAAAAAsdasdk8LF81IU...jCpTnA',
'Referer': 'https://twitter.com/taylorswift13',
'Connection': 'keep-alive',
}
params = {
'variables': '{"userId":"17919972","count":40,"cursor":"HBaAwLTRytqKnSIAAA==","includePromotedContent":true,"withQuickPromoteEligibilityTweetFields":true,"withSuperFollowsUserFields":true,"withDownvotePerspective":false,"withReactionsMetadata":false,"withReactionsPerspective":false,"withSuperFollowsTweetFields":true,"withVoice":true,"withV2Timeline":true}',
'features': '{"dont_mention_me_view_api_enabled":true,"interactive_text_enabled":true,"responsive_web_uc_gql_enabled":false,"vibe_tweet_context_enabled":false,"responsive_web_edit_tweet_api_enabled":false,"standardized_nudges_misinfo":false,"responsive_web_enhance_cards_enabled":false}',
}
response = requests.get('https://twitter.com/i/api/graphql/LeRJx69CS_6El2rAG0HQ9g/UserTweets', params=params, cookies=cookies, headers=headers)
运行结果
json很长很长,没人会看的
设计爬虫
代码
老三样,请求,处理,持久化,程序很长的时候就需要写一个调度器
代码和结构奉上
这四个文件都是同一目录下的
conf.py 配置
Click to see more
# -*-coding:utf-8-*-
# SettingCode here
COOKIES = {
...
}
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:101.0) Gecko/20100101 Firefox/101.0',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'content-type': 'application/json',
# 推特自己整的header 不配置就403
'x-twitter-auth-type': 'OAuth2Session',
'x-twitter-client-language': 'zh-cn',
'x-twitter-active-user': 'yes',
# csrf token 可能会变
'x-csrf-token': '1b73c3ff3f8905027c09c83f2529sdasdasbc45ed03d998458ced11b1c1c3d6a65c07e4b67f2f67c715a0728ccd2bb445956c',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
# 这个字段不知道干嘛的,但是很明显不是自带的
'authorization': 'Bearer AAAAAAAAAAAAAAAsdsadsadZz4puTs%3D1Zv7ttfk8LF81IUq16cHjhLTvJu4FA33AGWWjCpTnA',
'Referer': "",
'Connection': 'keep-alive',
}
PROXY = {
'http': 'http://127.0.0.1:7890',
'https': 'http://127.0.0.1:7890',
}
# 爬哪个用户
USERID = 17919972
CRAWLED_PIN = 0 # 制定是否被爬过
TIMELINE_SLEEP = 15 # 每个timeline线程每次请求间隔时间
DETAIL_SLEEP = 15 # 每个推文请求间隔
运行结果
scheduler.py 主程序,调度
Click to see more
# -*-coding:utf-8-*-
# SettingCode here
__author__ = "a_little_rubbish"
__date__ = "2022/7/5 15:06"
# import your model here
import time
from contextlib import contextmanager
from queue import Empty
import multiprocessing
from multiprocessing import Manager
import timeline_spider
import detail_spider
import persistence
from conf import *
def is_done(status_table, p_type):
"""
检查某一类线程是否全都结束了
:param status_table: 状态表
:param p_type: 线程类型
:return:
""" done = []
print("ProcessStatus:", status_table)
for k, v in status_table[p_type].items(): # 遍历状态表
if v == 0: # 添加状态
done.append(True)
else:
done.append(False)
return all(done) # 全完成就返回Tuee
@contextmanager
def process_info_logger(status_table, p_type, p_name):
"""
进程函数状态管理
:param status_table: 状态表
:param p_type: 哪类进程
:param p_name: 进程名,初始化用
:return:
""" temp = status_table[p_type] # 进程嵌套字典需要中间转一下赋值
temp[p_name] = 1
status_table[p_type] = temp
print("%s starting..." % p_name)
yield
temp = status_table[p_type] # 进程结束
temp[p_name] = 0
status_table[p_type] = temp
print("%s has done" % p_name)
def timeline_crawler(status_table, detail_Q):
"""
爬时间线的进程函数
只能起一个,多用户才能多个,因为不能切片只能下滑
""" name = multiprocessing.current_process().name
with process_info_logger(status_table, "timeline", name):
cursor = "" # 第一次为空
while True:
try:
result = timeline_spider.crawl(cursor)
except Exception as e: # 出现错误就返回
print(e)
break
if result == 0: # 这个人的已经爬完了
break
for i in result["detail_list"]:
detail_Q.put(i) # 结果加进去
cursor = result["cursor"] # 获得下一次的标
time.sleep(TIMELINE_SLEEP) # 控制频率
def detail_crawler(status_table, detail_Q, ready_data_Q):
"""
爬推文细节的进程函数,放到ready_data_Q
""" name = multiprocessing.current_process().name
with process_info_logger(status_table, "detail", name):
while True:
try:
tw_id = detail_Q.get(timeout=3)
except Empty as e:
if is_done(status_table, "timeline"):
break
continue except Exception as e:
print(e)
break
ready_data = detail_spider.crawl(tw_id)
ready_data_Q.put(ready_data)
time.sleep(DETAIL_SLEEP) # 控制频率
def persist(status_table, ready_data_Q):
"""
从ready_data_Q拿数据持久化,存数据库
""" name = multiprocessing.current_process().name
with process_info_logger(status_table, "persist", name):
while True:
try:
data = ready_data_Q.get(timeout=3)
except Empty as e:
if is_done(status_table, "detail"):
break
continue persistence.persist_sql(data)
def main():
"""
主函数
""" pool = []
for i in range(1, 2): # 爬时间线的线程
p = multiprocessing.Process(target=timeline_crawler,
args=(status_table, detail_Q),
name='timelineCrawlr%d' % i)
pool.append(p)
for i in range(1, 3): # 爬推文的线程
p = multiprocessing.Process(target=detail_crawler,
args=(status_table, detail_Q, ready_data_Q),
name='detailCrawler%d' % i)
pool.append(p)
for i in range(1, 3): # 持久化线程
p = multiprocessing.Process(target=persist,
args=(status_table, ready_data_Q),
name='persister%d' % i)
pool.append(p)
for i in pool:
i.start()
for i in pool:
i.join()
if __name__ == '__main__':
status_table = Manager().dict({"timeline": {}, "detail": {}, "persist": {}}) # 进程状态表,1是运行,0是运行结束
detail_Q = Manager().Queue(maxsize=200) # 每个tweet的id队列
ready_data_Q = Manager().Queue(maxsize=200) # 就绪数据队列\
persistence.init_table() # 初始化数据库
main()
运行结果
2022-07-06 15:11:52,653 INFO sqlalchemy.engine.Engine SELECT DATABASE()
2022-07-06 15:11:52,653 INFO sqlalchemy.engine.Engine [raw sql] {}
2022-07-06 15:11:52,666 INFO sqlalchemy.engine.Engine SELECT @@sql_mode
2022-07-06 15:11:52,667 INFO sqlalchemy.engine.Engine [raw sql] {}
2022-07-06 15:11:52,667 INFO sqlalchemy.engine.Engine SELECT @@lower_case_table_names
2022-07-06 15:11:52,667 INFO sqlalchemy.engine.Engine [raw sql] {}
2022-07-06 15:11:52,680 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2022-07-06 15:11:52,681 INFO sqlalchemy.engine.Engine SELECT COUNT(*) FROM information_schema.tables WHERE table_schema = %(table_schema)s AND table_name = %(table_name)s
2022-07-06 15:11:52,681 INFO sqlalchemy.engine.Engine [generated in 0.00012s] {'table_schema': 'twitter', 'table_name': 'posts'}
2022-07-06 15:11:52,768 INFO sqlalchemy.engine.Engine
DROP TABLE posts
2022-07-06 15:11:52,768 INFO sqlalchemy.engine.Engine [no key 0.00022s] {}
2022-07-06 15:11:52,958 INFO sqlalchemy.engine.Engine COMMIT
2022-07-06 15:11:52,964 INFO sqlalchemy.engine.Engine BEGIN (implicit)
2022-07-06 15:11:52,964 INFO sqlalchemy.engine.Engine SELECT COUNT(*) FROM information_schema.tables WHERE table_schema = %(table_schema)s AND table_name = %(table_name)s
2022-07-06 15:11:52,964 INFO sqlalchemy.engine.Engine [cached since 0.2835s ago] {'table_schema': 'twitter', 'table_name': 'posts'}
2022-07-06 15:11:52,975 INFO sqlalchemy.engine.Engine
CREATE TABLE posts (
id INTEGER NOT NULL AUTO_INCREMENT,
main_posts TEXT NOT NULL,
reply TEXT,
PRIMARY KEY (id)
)
2022-07-06 15:11:52,975 INFO sqlalchemy.engine.Engine [no key 0.00009s] {}
2022-07-06 15:11:53,110 INFO sqlalchemy.engine.Engine COMMIT
detailCrawler2 starting...
detailCrawler1 starting...
persister2 starting...
persister1 starting...
timelineCrawlr1 starting...
status 200 crawing timelineSlice
extracting timeline data
ProcessStatus: ProcessStatus: {'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
{'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
status 200 crawing tweets 1459023801480474632
status 200 crawing tweets 1540382753677627393
extracting tweets data 1540382753677627393
extracting tweets data 1459023801480474632
inserting data {'posts': ['I’m absolutely terrified that this is where we are - that after so many decades of people fighting for women’s rights to their own bodies, today’s decision has stripped us of that.'], 'reply': ['@taylorswift13 A baby’s body is *not* your body. Let them live. Abortion is violence.', '@taylorswift13 why on earth does a gun have more protection in this country than i do??', '@taylorswift13 You may have lost a fan unless I’m misunderstanding you. Abortion is murder. Contraceptives should be used if you’re having sex and can’t handle/don’t want to have a child. In certain cases (rape, woman’s health etc…) an abortion should be an option…', '@taylorswift13 I don’t understand why everyone is upset… if you don’t want a baby just don’t get pregnant… right? And if you do, why just remove the existence of the fetus inside you, that you were once yourself, erasing their entire future and existence because you don’t want them? \U0001fae5', '@taylorswift13 Kindly explain why women who fight so hard for their own bodies find it so easy to destroy someone else’s (a baby’s, no less). Take your time, I’ll wait. (By the way, hundreds of babies were scheduled to die today, but now won’t. Does their reprieve make you happy or sad?)', '@taylorswift13 So disappointed in myself that I used to look up to you as a teenager! Taylor, your mother chose life, and chose to have you. If it wasn’t for her choosing life, you wouldn’t even have rights.', '@taylorswift13 I’m soooo disappointed to hear you say this … nobody should be able to choose to end someone else’s life. No matter how old the person is, (fetus, 5 year’s old or 40 years old) it’s a living being. The women’s choice was to have sex, so they need to deal with the consequences.', '@taylorswift13 @BlueberryGabe I’m terrified of a centralized government dictating what all of us have to believe. I am less terrified now that the states have the individual power to decide what for their local cultures. If you’re really that worried take a morning-after pill. Does the same thing.', '@taylorswift13 @Kenshiro73 That’s just the start. They won’t stop there. \n\nhttps://t.co/h8xzUX5FPx']}
inserting data {'posts': ['It never would have been possible to go back & remake my previous work, uncovering lost art & forgotten gems along the way if you hadn’t emboldened me. Red is about to be mine again, but it has always been ours. Now we begin again. Red (my version) is out\n\nhttps://t.co/ZUAWDuv4jL https://t.co/Ji26KdOlWQ', 'https://pbs.twimg.com/media/FD9-aXKWYAATZTm.jpg', 'https://pbs.twimg.com/media/FD9-aXIWYBI4DP6.jpg'], 'reply': ['@taylorswift13 i just wanna say that the very first night is one of the best vauIt track ever 😎 thanks for this b0p song😿❤️ \n https://t.co/Z86fmElt6A', '@taylorswift13 yassss speak now tv announcement!!\nhttps://t.co/S6U0tbJBCi', '@taylorswift13 ei tweeta aí https://t.co/SasFRYPgau', "@taylorswift13 OMG it's here 🥺❤️", "@taylorswift13 Best singer in the world is miss Taylor swift lady's and gentlemen love voodoo XX https://t.co/1iI3DjRoxd", "@taylorswift13 Tomorrow (Dhul-Hijjah 1st / July 1st) is Muslims valentine day due to the anniversary of a shining marriage of a sacred couple Ali & Fatemah. Their brilliant love is still an ideal one for marriage of many muslims and that's the reason they mostly have a great family.\n#pure_love", '@taylorswift13 Why do you have tour dates in venues that are 21 and older? You’re cutting off a lot of fans.', '@taylorswift13 A red rose grew up out of ice frozen ground, with no one around to tweet it. https://t.co/nB7KX5SzJH', '@taylorswift13 World s best singer ever. Miss Taylor swift best album ever sold red album bye miss Taylor swift love voodoo XX my queen my love for ever XX https://t.co/slWOh6Q9xr']}
ProcessStatus: {'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
ProcessStatus: {'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
ProcessStatus: {'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
ProcessStatus: {'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
ProcessStatus: ProcessStatus: {'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
{'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
ProcessStatus: ProcessStatus: {'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
{'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
ProcessStatus: {'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
ProcessStatus: {'timeline': {'timelineCrawlr1': 1}, 'detail': {'detailCrawler2': 1, 'detailCrawler1': 1}, 'persist': {'persister2': 1, 'persister1': 1}}
status 200 crawing timelineSlice "cursor":"HBaOgKPFjJfCwCcAAA==",
extracting timeline data HBaOgKPFjJfCwCcAAA==
status 200 crawing tweets 1540183720845533185
extracting tweets data 1540183720845533185
inserting data {'posts': ['About a year & half ago I wrote a song about the story of a girl who always lived on the outside, looking in. Figuratively & literally. The juxtaposition of her loneliness & independence. Her curiosity & fear all tangled up. Her persisting gentleness & the world’s betrayal of it. https://t.co/2o1z8Hrht6', 'https://pbs.twimg.com/ext_tw_video_thumb/1540183648468623360/pu/img/xHEqJJY-HYNZqQTZ.jpg'], 'reply': ['I wrote this one alone in the middle of the night and then @AaronDessner and I meticulously worked on a sound that we felt would be authentic to the moment when this story takes place. I made a wish that one day you would hear it. ‘Carolina’ is out now 🥺 \nhttps://t.co/2xqE0fEr10', '@taylorswift13 Thank for the song Taylor! Now please leave folkmore forest so that we can get TS10 yeah?', '@taylorswift13 Wen a song about leprechauns? @Leprechaun_Wtf #Leprechauntownwtf #LeprechaunTakeOver https://t.co/7aus6zadZd', '@taylorswift13 @jeonality @worthwhilefigh1 this is what u get for being optimist ;)', '@taylorswift13 @Leprechaun_Wtf got talent ms swift check out our theme song by the one and only @LiggyNFT', '@taylorswift13 my favorite tagline to see nowadays 🤍 https://t.co/PGjxahqHx6', '@taylorswift13 Get in Swifties, we’re going to the swamp! #Carolina https://t.co/vOVYgXqNGo', '@taylorswift13 Taylor only used instruments that were available before 1953 and Taylor recorded the song in one take like they did back then… no one is as extra as Ms. Swift https://t.co/4TPF4YWNUV']}
status 200 crawing tweets 1529295926057123841
extracting tweets data 1529295926057123841
inserting data {'posts': ['Filled with rage and grief, and so broken by the murders in Uvalde. By Buffalo, Laguna Woods and so many others. By the ways in which we, as a nation, have become conditioned to unfathomable and unbearable heartbreak. Steve’s words ring so true and cut so deep.'], 'reply': ['@taylorswift13 de la nada no', "@taylorswift13 We should never get used on violence, no matter how many times we turn on the news just to see it all again. It is not just a number, is someone's daughter as you said in epiphany. As a health worker that deals with mothers in grief daily it breas my heart for each family.", "@taylorswift13 As a Canadian, I hate to say it, but nothing will change. Absolutely nothing. Your government officials offer thoughts and prayers every single time, as if that's going to fix things. I guarantee someone has said there should have been an armed guard at the school. 🤬🤬🤬", '@taylorswift13 If there are 50 senators refusing to vote, how are they still in office (if, essentially, they are refusing to do their job?) \n\nSomeone please (nicely) educate me', '@taylorswift13 What this shows is not the relationship between mental illness and gun violence, but between virtually unregulated access to assault weapons and gun violence. This has to change because it has to. Right now. https://t.co/e1cWDwkpOC', '@taylorswift13 I can’t imagine what it’s like to be a parent in the US. Knowing that every day you send your kids to school, it might be the last time. Every time you kiss them in the morning, it might be the last kiss. I don’t live in the US, I can’t affect its politics. But US lawmakers can!', '@taylorswift13 Thank you for speaking out on this, it’s feeling like nothing will ever change & this will just keep happening regularly because that’s the reality we live in 💔', '@taylorswift13 We are all so tired, sad & angry. I was a teen when Columbine happened. 23 yrs, we’ve had 23 yrs to do SOMETHING. And yet we’ve done NOTHING. Elected officials have the ability to do SOMETHING. Remember that. We’ve had ENOUGH. Our country stands alone in #s of mass shootings. 1/2', '@taylorswift13 swifties pls don’t make this ab u', '@taylorswift13 Taylor. Or Taylor social media person. Girl where are you on Roe v Wade??? I thought maybe you were just not getting out there on any current events or legislation, but this tweet? So you’re out here. Say something about abortion. Or tell us you’re pro life.']}
...
...
...
timeline_spider.py 爬时间线
Click to see more
# -*-coding:utf-8-*-
# SettingCode here
__author__ = "a_little_rubbish"
__date__ = "2022/7/5 09:11"
# import your model here
import time
from pprint import pprint
import requests
from requests.exceptions import ProxyError
from conf import *
# your class&function here
# userId 会根据不同用户变,%s处是cursor
PARAMS_ = {
'variables': '{"userId":"%d","count":40,%s"includePromotedContent":true,"withQuickPromoteEligibilityTweetFields":true,"withSuperFollowsUserFields":true,"withDownvotePerspective":false,"withReactionsMetadata":false,"withReactionsPerspective":false,"withSuperFollowsTweetFields":true,"withVoice":true,"withV2Timeline":true}',
'features': '{"dont_mention_me_view_api_enabled":true,"interactive_text_enabled":true,"responsive_web_uc_gql_enabled":false,"vibe_tweet_context_enabled":false,"responsive_web_edit_tweet_api_enabled":false,"standardized_nudges_misinfo":false,"responsive_web_enhance_cards_enabled":false}',
}
TIMELINE_URL = "https://twitter.com/i/api/graphql/LeRJx69CS_6El2rAG0HQ9g/UserTweets"
def crawl(cursor, userId=USERID):
"""
外部调用这个函数
解析一次timeline的cursor
:return: {detailList:int list,cursor:str }
""" raw_json = download(cursor, userId)
if raw_json == -1:
return "ERROR"
result = extract(raw_json, cursor)
return result
def extract(data, cursor):
"""
处理json
:param cursor: 为了打印日志好看
:param data raw_json :return: {detail_list:int list,cursor:str }
""" global CRAWLED_PIN
print("extracting timeline data %s " % cursor)
# 取数据,没什么好说的,结构长什么样就怎么取
detail_list = []
cursor_next = ""
instructions = data["data"]["user"]["result"]["timeline_v2"]["timeline"]["instructions"]
entries = []
for i in instructions:
if i["type"] == "TimelineAddEntries": # 时间线id
entries = i["entries"]
if len(entries) == 2:
return 0 # 代表线程已经爬完,告诉外面结束
if i["type"] == "TimelinePinEntry": # 拿置顶推的id
if CRAWLED_PIN == 0: # 每次请求都会带置顶,爬一次就行
entry_id = i["entry"]["entryId"].split("-")<br/>[1]
detail_list.append(entry_id)
CRAWLED_PIN = 1
for entry in entries:
entry_id = entry["entryId"]
if entry_id.startswith(("promotedTweet", "whoToFollow", "cursor-top")): # 推广和建议关注都不要
continue
elif entry_id.startswith(("tweet", "homeConversation")):
entry_id = entry_id.split("-")<br/>[1]
detail_list.append(entry_id)
elif entry_id.startswith("cursor-bottom"):
cursor_next = entry["content"]["value"]
return {"detail_list": detail_list, "cursor": cursor_next}
def download(cursor, userId):
"""
请求并判断连接状态处理
:param cursor userId :return: raw_json
""" if cursor != "":
cursor = '"cursor":"%s",' % cursor # 控制下拉加载什么的参数,首次请求没有,之后每次下拉加载都会在json里存放下一次的,每次都会刷新
PARAMS = PARAMS_.copy()
PARAMS["variables"] = PARAMS["variables"] % (userId, cursor)
while True:
try:
response = requests.get(TIMELINE_URL, proxies=PROXY, params=PARAMS, cookies=COOKIES, headers=HEADERS)
except ProxyError or ConnectionResetError:
print("timeline:ConnectionResetError")
time.sleep(20)
continue
break
if response.status_code != 200: # 请求错误就向上传递
print("error %d when crawing timelineSlice %s " % (response.status_code, cursor))
return -1
print("status %d crawing timelineSlice %s " % (response.status_code, cursor))
return dict(response.json())
if __name__ == "__main__":
crawl("HBaOgKPFjJfCwCcAAA==")
运行结果
status 200 crawing timelineSlice "cursor":"HBaOgKPFjJfCwCcAAA==",
extracting timeline data HBaOgKPFjJfCwCcAAA==
detail_spider.py 爬细节
Click to see more
# -*-coding:utf-8-*-
# SettingCode here
__author__ = "a_little_rubbish"
__date__ = "2022/7/5 15:06"
import time
import requests
from requests.exceptions import ProxyError
from conf import *
PARAMS_ = { # 不能直接修改
'variables': '{"focalTweetId":"%d","with_rux_injections":false,"includePromotedContent":true,"withCommunity":true,' # 这个focalTweetId是推文的详情
'"withQuickPromoteEligibilityTweetFields":true,"withBirdwatchNotes":true,'
'"withSuperFollowsUserFields":true,"withDownvotePerspective":false,"withReactionsMetadata":false,' '"withReactionsPerspective":false,"withSuperFollowsTweetFields":true,"withVoice":true,' '"withV2Timeline":true}',
'features': '{"dont_mention_me_view_api_enabled":true,"interactive_text_enabled":true,'
'"responsive_web_uc_gql_enabled":false,"vibe_tweet_context_enabled":false,' '"responsive_web_edit_tweet_api_enabled":false,"standardized_nudges_misinfo":false,' '"responsive_web_enhance_cards_enabled":false}',
}
DETAIL_URL = 'https://twitter.com/i/api/graphql/0vaSJ4y9SDdSPPZ72dpuDA/TweetDetail'
def crawl(tw_id):
"""
外部调用这个函数
:return:{posts:str,reply:str list}
""" tw_id = int(tw_id)
raw_json = download(tw_id)
if raw_json == -1:
return "ERROR"
result = extract(raw_json, tw_id)
return result
def extract(data, tw_id):
"""
解析返回的json
:param tw_id: 打印日志好看
:param data 接收原始json
:return {posts:str list,reply:str list} """
print("extracting tweets data %s " % tw_id)
# 取数据,没什么好说的,结构长什么样就怎么取,有问题就是json里面有没有值
posts = []
entries = []
try:
instructions = data["data"]["threaded_conversation_with_injections_v2"]["instructions"]
except KeyError as e:
print(e)
print("ERROR:",tw_id,data)
return {'posts': ["key threaded_conversation_with_injections_v2 error"],'reply': []}
for i in instructions:
if i["type"] == "TimelineAddEntries":
entries = i["entries"]
post = entries[0]["content"]["itemContent"]["tweet_results"]["result"]["legacy"]["full_text"]
posts.append(post)
media = entries[0]["content"]["itemContent"]["tweet_results"]["result"]["legacy"].get("extended_entities", "")
if media != "":
for i in media["media"]:
posts.append(i["media_url_https"])
reply = []
for entry in entries[1:-1]:
_ = entry["content"]["items"][0]["item"]["itemContent"]["tweet_results"]["result"].get('tombstone', False) # 处理封禁账号的消息
if _:
print("消息来自已封禁账号")
continue
_ = entry["content"]["items"][0]["item"]["itemContent"]["tweet_results"]["result"]["legacy"]["full_text"]
reply.append(_)
return {"posts": posts, "reply": reply}
def download(tw_id):
"""
:param tw_id: 该条推文的id
:return:
""" PARAMS = PARAMS_.copy()
PARAMS['variables'] = PARAMS['variables'] % tw_id
while True:
try:
response = requests.get(DETAIL_URL, params=PARAMS, cookies=COOKIES, headers=HEADERS)
except ProxyError or ConnectionResetError:
print("deatil:ConnectionResetError")
time.sleep(20)
continue
break if response.status_code != 200: # 返回码错误就向上传递
print("error %d when crawing tweets %d " % (response.status_code, tw_id))
return -1
print("status %d crawing tweets %d" % (response.status_code, tw_id))
return dict(response.json())
if __name__ == "__main__":
print(crawl(557649460810248194))
print(crawl(899647503859032065))
运行结果
persistence.py持久化
Click to see more
# -*-coding:utf-8-*-
# SettingCode here
__author__ = "a_little_rubbish"
__date__ = "2022/7/6 10:00"
from sqlalchemy import Column, String, Integer, Text, create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base() # 生成Model类的基类
class Posts(Base):
# 表的名字:
__tablename__ = 'posts'
# 表的结构:
id = Column(Integer, nullable=False, autoincrement=True, primary_key=True) # 资增int主键
main_posts = Column(Text, nullable=False) # 主推文
reply = Column(Text) # 回复
def __repr__(self):
return 'Posts(id={}, posts={}, reply={})'.format(self.id, self.main_posts, self.reply)
def __str__(self):
return self.__repr__()
def init_table():
engine = create_engine('mysql+pymysql://root:1118@127.0.0.1:3306/twitter', echo=True)
Base.metadata.drop_all(engine) # 删除所有表
Base.metadata.create_all(engine) # 创建所有表
def persist_sql(data):
"""
持久化到sql的函数
:param data: json数据,存sql
:return:
""" engine = create_engine('mysql+pymysql://root:1118@127.0.0.1:3306/twitter', echo=False)
Session = sessionmaker(bind=engine)
session = Session()
# 格式变一下
main_posts = ";".join(data["posts"])
reply = ";".join(data["reply"])
print("inserting data", data)
# 插入
p = Posts(main_posts=main_posts, reply=reply)
session.add(p)
try:
session.commit()
except Exception as e:
session.rollback()
raise e
if __name__ == "__main__":
# 测试数据
demodata = {'posts': [
'@DamonAlbarn I was such a big fan of yours until I saw this. I write ALL of my own songs. Your hot take is completely false and SO damaging. You don’t have to like my songs but it’s really fucked up to try and discredit my writing. WOW.'],
'reply': ['PS I wrote this tweet all by myself in case you were wondering 😑',
'@taylorswift13 I totally agree with you. i had a conversation about songwriting and sadly it was reduced to clickbait. I apologise unreservedly and unconditionally. The last thing I would want to do is discredit your songwriting. I hope you understand. - Damon',
'@taylorswift13 @Damonalbarn يابنت الحلال اطلعي خلاص وجع',
'@taylorswift13 @Damonalbarn Must you use foul language? I understand your point and im a Christian and this just is upsetting to see ladies use such language. Im a great grandmother, grandmother and mother....I like your music just the language is upsetting.',
'@taylorswift13 @Damonalbarn Just gonna leave this here. Look at all of these cowrites @Damonalbarn \n\n“Day doo de bop\nDay doo de bop” really required multiple writers to come up with that… https://t.co/aU8g9bD2rx',
"@taylorswift13 @Damonalbarn what the fuck taylor you can't just say fucking it's rude",
'@taylorswift13 @Damonalbarn OMG I JUST WOKE UP TO SEE TAYLOR SWIFT END A MAN YESSSSS https://t.co/3CAAXx1VGe',
'@taylorswift13 @Damonalbarn https://t.co/Qb8BbHxFSY',
'@taylorswift13 @Damonalbarn he’s just jealous he doesn’t have tons of awards like this shiny songwriter of the year 2020 award😌 https://t.co/JdwEN18dBT']}
init_table()
persist_sql(demodata)
运行结果
inserting data {'posts': ....
📌Tip
返回的json在处理的时候注意每次都会有置顶推,记得标记一下不要重复,还有判断边界条件什么时候停止进程
持久化的时候注意多进程的坑,每个进程一个engine,申请session这类的操错不要放在True中
多进程的变量只有第一层是共享的,多层嵌套的需要中间变量间接赋值才可以,代码里有
整体组织 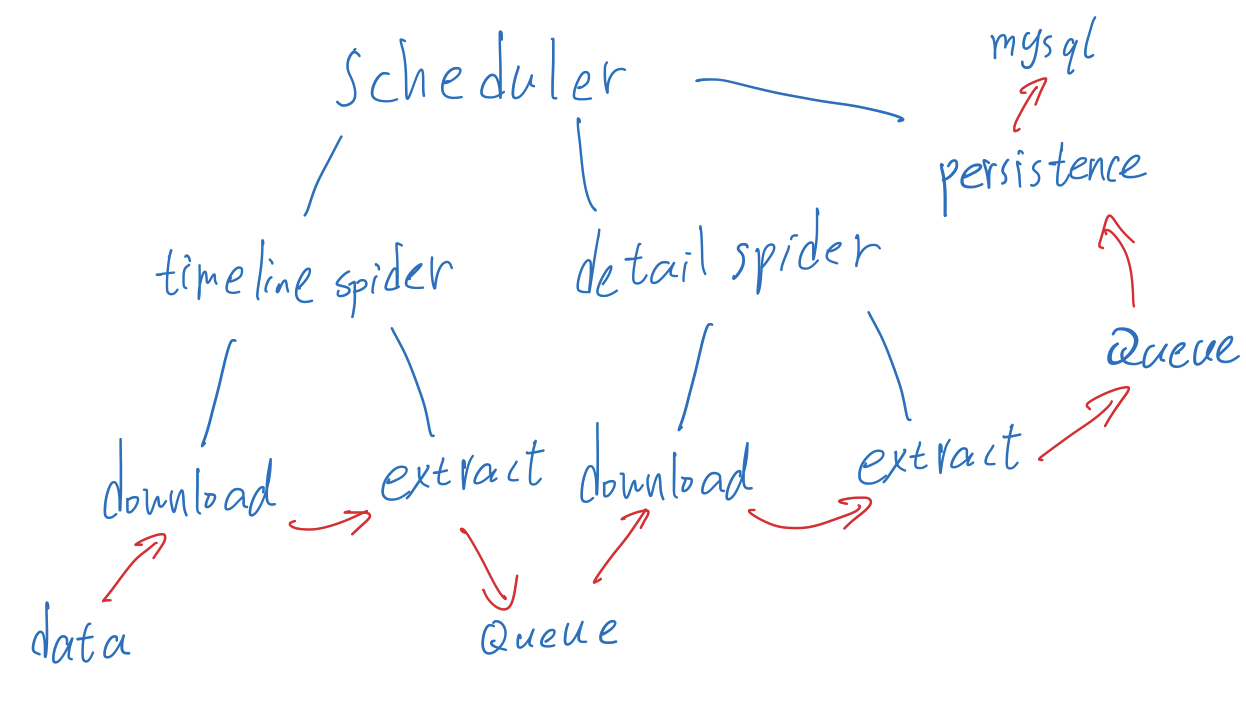 数据截图:
数据截图: 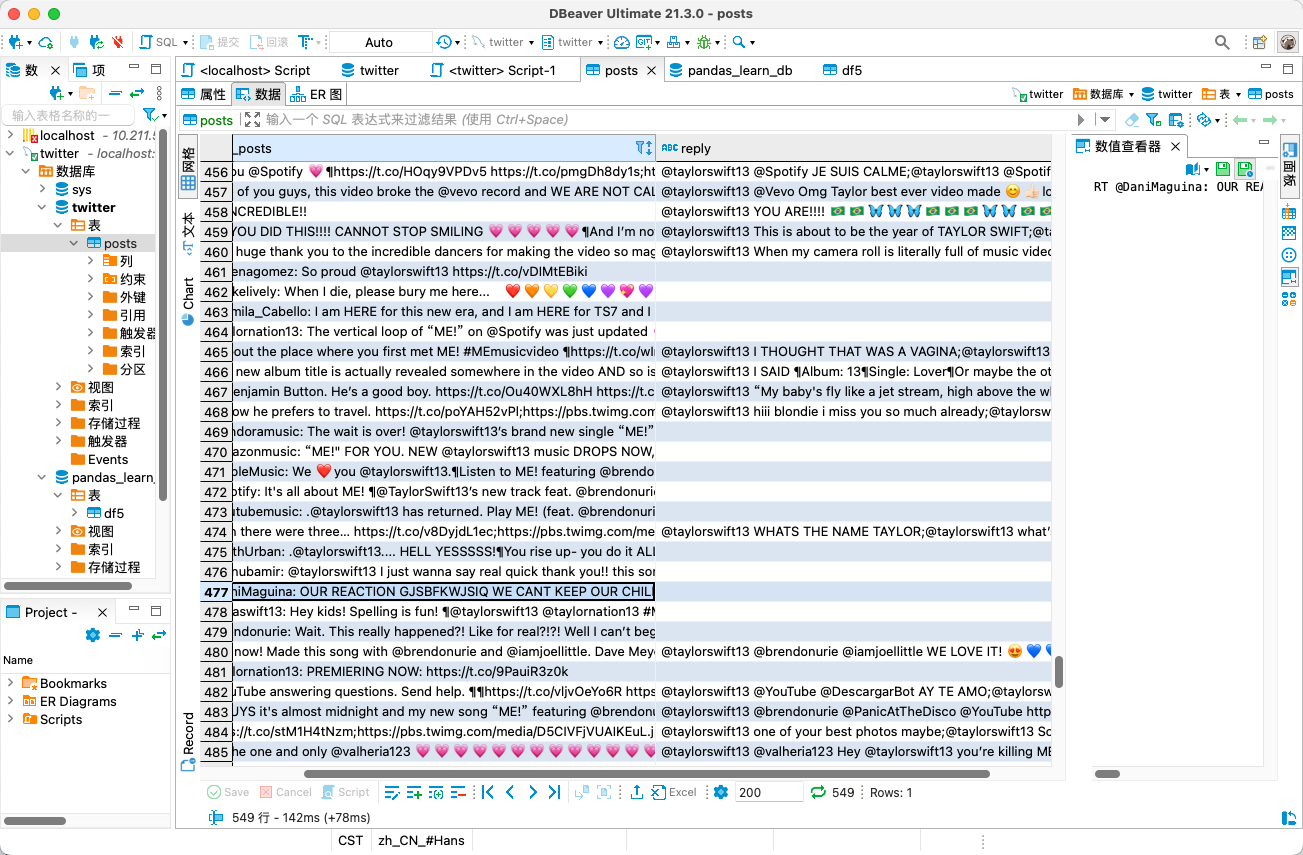
多进程
数据大致是这样,生产者1->消费者1->消费者2,通过队列连接进程,生产者1一个,消费者1三个,消费者2三个
此时生产者1完成之后,先检查数据是否完全放到队列中了,然后把状态表里自己的状态改为停止
消费者1取队列取不到之后等待三秒,try住错误,检查表中生产者1的状态,如果全关闭了那就是数据取完了,自己也关闭,改变表的状态。
后续消费者都如此。
这个程序启停是这样设计的。
反爬机制
推特主要就是频率限制和cookie,15秒一次动不动就reset connection,需要try之后等待再去请求,不要让进程里出现错误,否则进程就挂了
再就是请求头和cookie,都要带上,不然就过不去
问题
错误处理,日志方面还不完美,出现的错误都是直接try到了之后,打印信息跳过,继续下一次,没有设计足够的排查信息
日志没用logger,状态管理都是实时打印,很多冗余信息,也不知道应该打印哪些信息
线程状态管理应该配合错误处理
解析数据的时候其实我是直接写死的拿key,很不灵活,碰到的问题有 已经封禁账号发消息,不知道哪些请求没有数据,会报key error,写个try做一下处理,还有不知道这些json那个key没获取到的,没有评论数据,不过这种东西都不是必须的了,数据下来了想要就是早晚的事,这些也不是重点。
📄Info
爬虫有实效性,网站一变爬虫基本就跟着变
第二版v2
不是demo了,得拿上去部署,很多模块都得重新设计。
Last Edit: 2025-04-13 22:01:52